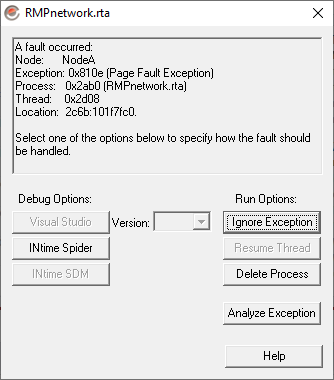
Leadshine CS3E Drive Fails to Enable
Regarding the behavior described below,
- What kind of troubleshooting can I do regarding failing to enable?
- What other kind of data/details could I gather to help diagnose this problem?
The Scenario
[RMP 10.3.8]
I have two devices exhibiting some unexpected (mis)behavior.
Starting with a vanilla RMP 10.3.8 distribution, I add the ESI files for these devices (CS3E_V1.20.xml, ESI_SI-ES3_2_02_Rev_02.xml) and added entries in NodeInfo.xml. (For details, see below.)
The Problem
The problem that I’ve observed is that the Leadshine drive will frequently not enable. Enabling fails without any sort of fault code from the drive or explicitly stated reason from RMP. It “seems” like it takes less than a second to fail, but it’s difficult to time it using RapidSetup. I’ve tried enabling via RapidCode, using
int32_t AmpEnableSet(bool enable, int32_t ampActiveTimeoutMilliseconds)
with a 5000 ms timeout, and it still fails to enable.
What I’ve observed is that if I do not shut down the network before stopping the RMP RTA (e.g. by stopping/restarting down the INtime node), then I will usually see this problem. If I do shut down the network before stopping the RMP RTA, then the problem behavior doesn’t happen. I can clear faults and enable the Leadshine drive.
When I do not shut down the network, the Leadshine will have a fault code of 0x821b, which their documentation describes as “Watchdog Time-Out of Synchronization Manager 2” with a suggested resolution of “Check the network cable.” I interpret this to mean that it lost contact with the EtherCAT master. That, at least would make sense based on my observations.
The curious observation is that this behavior does not happen at all if the GA500 is not present on the network. I can have the drive alone on the network or with some Beckhoff I/O slices and Yaskawa servo drives, and the behavior never happens, so long as the GA500 isn’t present.
Observations
- Both the Leadshine CS3E and GA500 must be on the network, with or without other nodes.
- The Leadshine drive must report 0x821b as a fault (after killing the EtherCAT master) in order for the bad behavior to happen.
- I can’t seem to make the problem happen by merely unplugging the ethernet cable from one of the objects on the network.
- The Leadshine drive does not appear to be doing a “wake and shake” that is thwarting RMP enable. (I see no change in reported positions.)
- The Leadshine sends fault codes via PDO, and the value of that object matches what RapidSetup reports on the axis view.
Problem Reproduction
- Start RapidSetup.
- Start the EtherCAT network.
- Close RapidSetup.
- Stop the EtherCAT master (restart INtime node).
- Start RapidSetup.
- Start the EtherCAT network.
- The Leadshine drive will have fault code 0x821b.
- Clear the fault.
- Attempt to enable the Leadshine.
- The Leadshine will fail to enable without any fault code returned.
Workaround
When the problem behavior is exhibited…
- Shut down the EtherCAT network.
- Start the EtherCAT network.
- Clear any faults on the Leadshine drive. (This is not essential, but I usually do it.)
- Enable the Leadshine drive.
- The drive will enable and stay enabled.
Verbose Details
Trace During AmpEnableSet()
I enabled tracing (RSITraceALL) for the RSI::RapidCode::Axis object when invoking AmpEnableSet(true,5000).
The trace log is 153,218 lines and 8.6 MiB. I don’t see obvious fires in the log (noting errors or failures).
The return values are generally 0x0, which I interpret to mean success. The calls that don’t return 0 are few.
mpiElementValidate(0xc1c338) returns 0x3
The others return what look like firmware memory addresses.
The lack of meaningful error/failure info means that I don’t have much data from that log to post here.
I can provide that info, if it would be useful.
NodeInfo.xml
Leadshine CS3E
<Vendor Id="0x4321"><VendorName>Leadshine Technology Co.,Ltd.</VendorName>
<Product Code="0x1200">
<ProductName>CS3E-D1008</ProductName>
<ShortName>Leadshine Stepper</ShortName>
<AxisCount>1</AxisCount>
<ItemSubType>Drive</ItemSubType>
<StatusWord>Transmit PDO 1.Status Word</StatusWord>
<PositionActual>Transmit PDO 1.Position Actual Value</PositionActual>
<ControlWord>Receive PDO 1.Control Word</ControlWord>
<PositionDemand>Receive PDO 1.Profile Target Position</PositionDemand>
<IO>
<DigitalInputItems>
<DigitalInput SigBits="0x00000600" Size="32" Home="2" PosLimit="1" NegLimit="0">Transmit PDO 1.Digital Inputs</DigitalInput>
</DigitalInputItems>
</IO>
</Product>
</Vendor>
Yaskawa GA500
<VendorName>Yaskawa</VendorName>
<Product Code="0x47413530">
<ProductName>Yaskawa GA500</ProductName>
<ShortName>Yaskawa VFD</ShortName>
<ItemSubType>Box</ItemSubType>
<PDOs>
<PDOAssignment Index="0x1600" IsOutput="True" Include="False"/>
<PDOAssignment Index="0x1623" IsOutput="True" Include="True">
<AddEntry Name="Selectable 1" Index="0x2080" SubIndex="1" BitLen="32" DataType="UDINT"/>
</PDOAssignment>
<PDOAssignment Index="0x1624" IsOutput="True" Include="True">
<AddEntry Name="Digital outputs" Index="0x20f0" SubIndex="1" BitLen="16" DataType="UINT"/>
</PDOAssignment>
<PDOAssignment Index="0x1627" IsOutput="True" Include="True"/>
<PDOAssignment Index="0x1628" IsOutput="True" Include="True"/>
<PDOAssignment Index="0x1a00" IsOutput="False" Include="False"/>
<PDOAssignment Index="0x1a23" IsOutput="False" Include="True"/>
<PDOAssignment Index="0x1a24" IsOutput="False" Include="True">
<AddEntry Name="Output current" Index="0x2120" SubIndex="1" BitLen="16" DataType="UINT"/>
</PDOAssignment>
<PDOAssignment Index="0x1a26" IsOutput="False" Include="True">
<AddEntry Name="Digital inputs" Index="0x2180" SubIndex="1" BitLen="16" DataType="UINT"/>
</PDOAssignment>
<PDOAssignment Index="0x1a27" IsOutput="False" Include="True">
<AddEntry Name="MEMOBUS write response" Index="0x2150" SubIndex="1" BitLen="32" DataType="UDINT"/>
</PDOAssignment>
</PDOs>
<IO>
<DigitalInputItems>
<DigitalInput SigBits="0xffff" Size="16">Inputs.Drive status</DigitalInput>
<DigitalInput SigBits="0xffff" Size="16">Inputs.Digital inputs</DigitalInput>
</DigitalInputItems>
<DigitalOutputItems>
<DigitalOutput SigBits="0xffff" Size="16">Outputs.Digital outputs</DigitalOutput>
</DigitalOutputItems>
</IO>
</Product>
...